如何玩转graphql
如何玩转graphql
本文介绍一下关于graphql的一些入门知识和使用技巧。
什么是graphql
-
一种用于 API 的查询语言。GraphQL 的强大表达能力主要还是来自于它完备的类型系统,与 REST 不同,它将整个 Web 服务中的全部资源看成一个有连接的图,而不是一个个资源孤岛,在访问任何资源时,都可以通过资源之间的连接访问其它的资源。
-
获取多个资源。只用一个请求GraphQL 这种方式能够将原有 RESTful 风格时的多次请求聚合成一次请求,不仅能够减少多次请求带来的延迟,还能够降低服务器压力,加快前端的渲染速度。它的类型系统也非常丰富,除了标量、枚举、列表和对象等类型之外,还支持接口和联合类型等高级特性
-
适用平台众多。GraphQL 与语言无关。而且它更多的是一个概念,可以根据官方规范用任何支持的语言(如 Ruby、Java 或 Python等等)来实现。
Graphql与RESTful对比

Grqphql 2012 年在Facebook内部开发,在 2015 年开源,RESTful RESTful的提出时间在2000年。
数据请求方式
对比之一:数据请求方式 例如,如果你想获取一个博客文章的标题,作者,评论和点赞数,你可能需要在REST API中发送四个请求,分别是:XXXX 而且每个请求可能会返回一些你不关心的数据,比如用户的邮箱,评论的时间,点赞的用户等。这就造成了过度获取和低效的网络传输。

- GET /posts/1
- GET /users/1
- GET /comments?post=1
- GET /likes?post=1
可能会造成服务器的
- 过度获取(OverFetching)
- 获取欠缺(UnderFetching)
与REST多个endpoint不同,每一个的 GraphQL 服务其实对外只提供了一个,用于调用内部接口的端点,所有的请求都访问这个暴露出来的唯一端点。 而在GraphQL中,你只需要发送一个请求,就可以获取你想要的数据,而不多也不少。你可以写一个这样的查询:

{
post(id: 1) {
title
author {
name
}
comments {
content
}
likeCount
}
}
{
"data": {
"post": {
"title": "GraphQL vs REST API",
"author": {
"name": "Aagam Vadecha"
},
"comments": [
{
"comments": "Great article!"
},
{
"comments": "Very informative"
}
],
"likeCount": 42
}
}
}
数据响应格式 && 数据关联方式 && 数据文档方式
- 数据响应格式
GraphQL使用JSON格式来返回数据,且数据的结构和查询的结构完全一致,方便客户端解析和使用。RESTful API也可以使用JSON格式来返回数据,但是数据的结构可能会因为不同的资源和操作而变化,需要客户端做更多的适配工作。
- 数据关联方式
前端拿到数据,解析速度更快,性能更好,也更方便,不需要客户端去做更多的合并和处理工作。
- 数据文档方式
GraphQL有一个自描述的类型系统,可以让开发者清楚地知道API可以提供哪些数据和操作,以及如何请求它们。GraphQL还有一些工具可以自动生成和浏览文档,比如GraphiQL。RESTful API则需要开发者手动编写和维护文档,或者使用一些标准和工具来生成文档,比如Swagger。
Graphql 以图的形式对外暴露资源
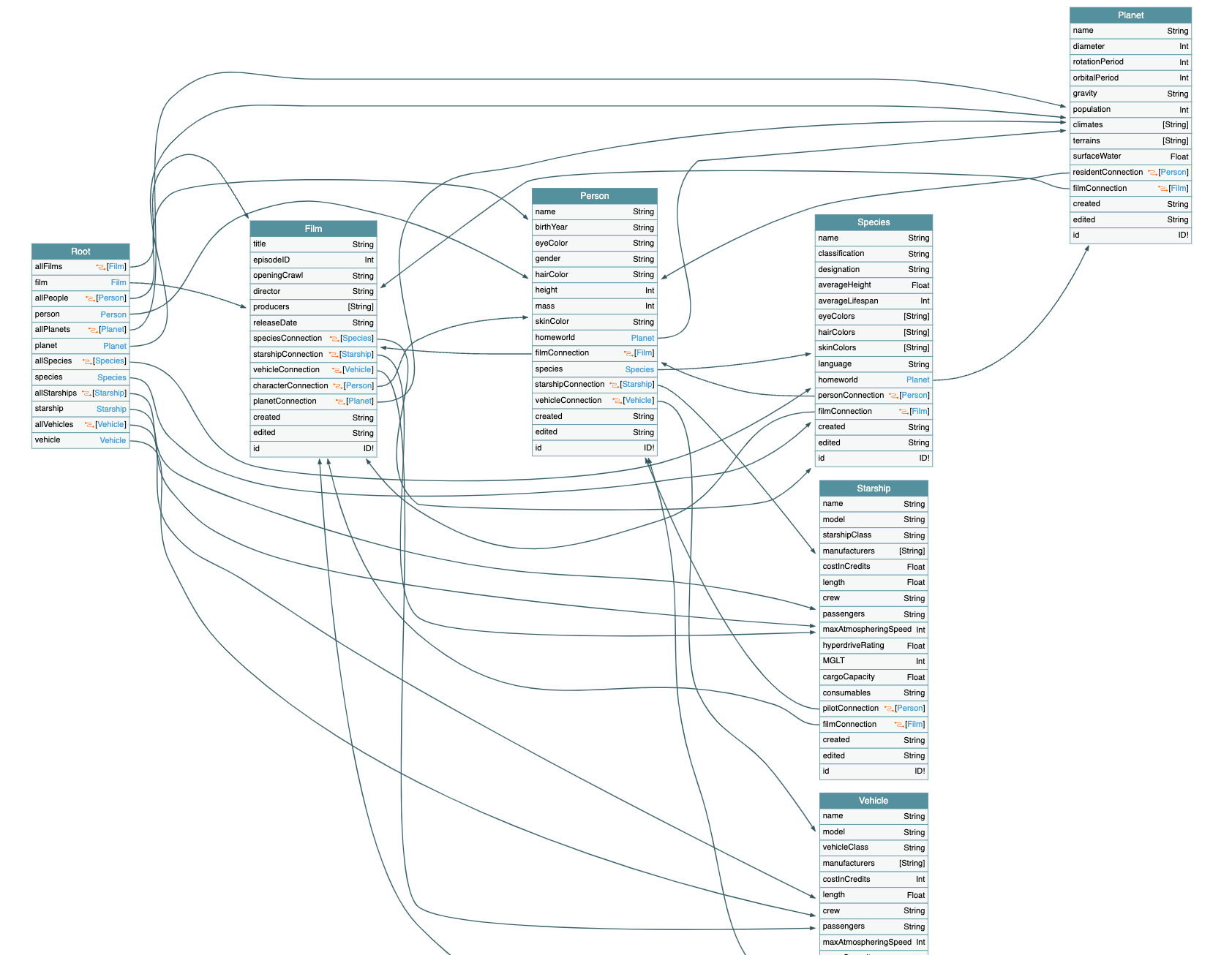
- 在它的设计思想中,GraphQL 以图的形式将整个 Web 服务中的资源展示出来,客户端可以按照其需求自行调用,类似添加字段的需求其实就不再需要后端多次修改了。
- 创建GraphQL服务器的最终目标是:允许查询通过图和节点的形式去获取数据。
graphql 如何工作的呢

编码 GraphQL 模式的语法称为 GraphQL 模式定义语言(SDL)。SDL 的类型系统允许开发者定义数据结构,在工程里定义好的schema文件也是graphql项目的核心。所有 GraphQL 模式都有三个特别的根(root)类型:Query, Mutation 和 Subscription。这 3 个基础类型分别负责 GraphQL 提供的三种操作类型:query,mutation 和 subscription。根类型下的字段被称为根字段(root field),它们定义了可用的 API 操作。
简单实例
- 我们来看一个简单例子,这里是定义了两个query类型的字段,一个mutation字段,一个自定义的User类型。其中String、ID都是scalar类型,标量类型,可以看作语言原生的数据类型。
type Query {
users: [User!]!
user(id: ID!): User
}
type Mutation {
createUser(name: String!): User!
}
type User {
id: ID!
name: String!
}
- 上边的代码是schema文件内容,下边的代码是在客户端发送请求的时候定义的请求内容。
# Query for all users
query {
users {
id
name
}
}
# Query a single user by their id
query {
user(id: "user-1") {
id
name
}
}
# Create a new user
mutation {
createUser(name: "Bob") {
id
name
}
}
graphql使用的痛点和一些解决方案
graphql技术也并非浑身上下都是宝,也有一些开发和使用上的痛点:
- Graphql 开发爽的貌似都是前端,已经采访过后端开发给出的一些- grapqhl开发的痛点:graphql本身是解决数据获取更加高效,让客户端可以自行决定获得的数据。当时随着开发组的增多,graphql规范中一个schema文件撸到底的模式则带来一些麻烦,schema文件的过度膨胀,难以维护。而当各个团队使用各自的子schema文件来开发和维护时,就造成了多个api接口暴露和数据的冗余,反而降低了graphql的优势。
- 随着业务逻辑的增加,GraphQL schema 确实会变得越来越大,这可能会导致性能下降、开山发效率降低以及难以维护等问题。以下是几种可以解决这个问题的方法:
- 分层架构:将 GraphQL schema 分为多个子schema, 每个子schema 独立且职责清晰, 这样可以降低整体 schema 的复杂度。
- 使用fragment: GraphQL fragment 是一个可重用的片段,可以用来组合多个查询。使用 fragment 可以使查询更加模块化和可重用。
- 延迟加载:将复杂的查询切分为多个较小的查询,只在需要的时候再去加载。这样可以提高性能,减少不必要的查询,同时也可以避免一次性加载大量数据而导致的性能问题。
- 自动化生成schema:可以使用工具自动生成 GraphQL schema,例如通过解析数据库结构、AP!等信息来生成 schema,这样可以减少手动编写schema 的工作量,并且可以保证schema 的正确性。 5.缓存:使用缓存可以避免重复查询,提高性能,并且可以减少对 schema 的依赖。例如, 可以使用 Redis 等缓存工具来缓存查询结果,以减少查询对数据库的依赖。 总之,针对复杂的 GraphQL schema,我们可以通过分层架构、使用 fragment、延迟加载、 自动化生成 schema 和缓存等方式来解决问题。
graphql的一些调试工具和库
- Grphiql
- Playground
- Altair
- Voyager
